March 8, 2026
5 min
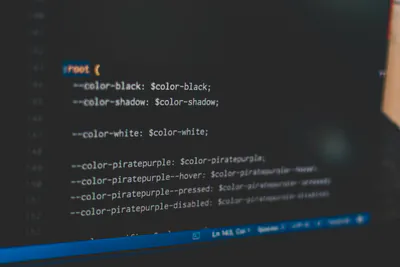
How to Avoid Style Conflicts in Micro-Frontend Architecture
Strategies to prevent global style leaks in distributed apps.

Traffic at 100k+ users per day rarely arrives as a smooth curve. It shows up as bursts: a push notification, a mention on social media, a morning commute pattern, or a weekly payroll run. The hard part is that most systems don’t fail evenly. One endpoint times out, one database table locks, one third-party integration stalls—and the rest of the app looks “down” to users even if most components are still alive.
High traffic is often described as “more requests,” but the real strain comes from amplification. A page that loads five resources becomes five chances to stall. A “simple” API call fans out into caches, databases, search, and billing. A single slow dependency can multiply into thousands of blocked connections when traffic spikes.
On the frontend, the bottleneck tends to be latency and payload size: users on mobile networks feel every extra script and every cache miss. On the backend, the bottleneck tends to be contention: too many concurrent requests fighting over the same hot rows, the same rate-limited service, or the same limited pool of workers.
For web apps under heavy load, the frontend strategy is mostly about making the network predictable. CDNs absorb demand better than origin servers, but only if assets are cacheable and versioned. When HTML can’t be cached, teams lean on cached data fragments, edge rendering, or careful separation between what must be personalized and what can stay static.
Under load, “performance” becomes an availability feature. Large JavaScript bundles translate into long main-thread blocks, which look like outages to real users. The practical response is usually boring: reduce dependencies, split bundles where it matters, and treat third-party scripts like potential incidents. Many high-traffic sites end up with rules for what can run on the critical path and what must be deferred, sandboxed, or removed.
Backend capacity isn’t only about adding servers. It’s about preventing synchronized work. Caches help, but the failure mode is well known: a cold cache or an expired key can stampede the database. Systems that hold up under pressure tend to include protection against this, such as request coalescing, stale-while-revalidate behavior, and sensible time-to-live choices that avoid expiring everything at once.
Databases usually become the center of gravity. At 100k daily users, problems often come from a few hotspots: a popular feed query, a global counter, an “unread notifications” table, or an overused search pattern. The fixes are typically structural: denormalizing where it reduces joins, adding read replicas, moving analytics queries off the primary, and designing indexes around real access patterns rather than theoretical ones.
As traffic grows, teams also become more intentional about background work. Anything that doesn’t need to happen in the request path—image processing, email sending, recomputing recommendations—moves to queues. This isn’t just about speed; it’s about keeping the system responsive when something downstream slows down.
At scale, it’s safer to assume partial failure will happen. Timeouts, circuit breakers, and rate limits are not “optimizations”; they’re boundaries that keep one bad dependency from taking the whole product with it. A common pattern is to degrade features: show cached content, hide nonessential widgets, or delay expensive personalization when the system is under stress. Users tend to tolerate simplification better than spinning loaders and errors.
Many scaling problems aren’t discovered in architecture diagrams but in production behavior. Logs, metrics, and traces become the way teams locate the single slow query or the one endpoint that leaks memory. Capacity planning also turns concrete: understanding peak-to-average ratios, tracking queue depth, watching database connection counts, and noticing when retries are creating their own denial-of-service.
High traffic rarely “breaks the app” all at once. It breaks assumptions: that dependencies are fast, that caches are warm, that databases are idle, and that errors are rare.
Handling 100k+ daily users is less about heroic scaling moves and more about systematic reduction of avoidable work, isolation of failures, and careful attention to the few places where demand concentrates.
Let's discuss how I can help bring it to life. I'm happy to answer questions and suggest possible solutions.
Contact me